Perplexity隱身避禁令|抓取網站內容 網安公司揭發 爬蟲AI遭攔截即扮瀏覽器
原文刊於信報財經新聞「CEO AI⎹ EJ Tech」
美國人工智能(AI)搜尋引擎Perplexity,一直從互聯網抓取文本、圖像及影片等數據,以確保旗下產品得以正常運行。部分網站為阻截爬蟲機械人,透過網絡標準檔案robots.txt,通知搜尋引擎及AI公司,哪些頁面可以或不被索引。
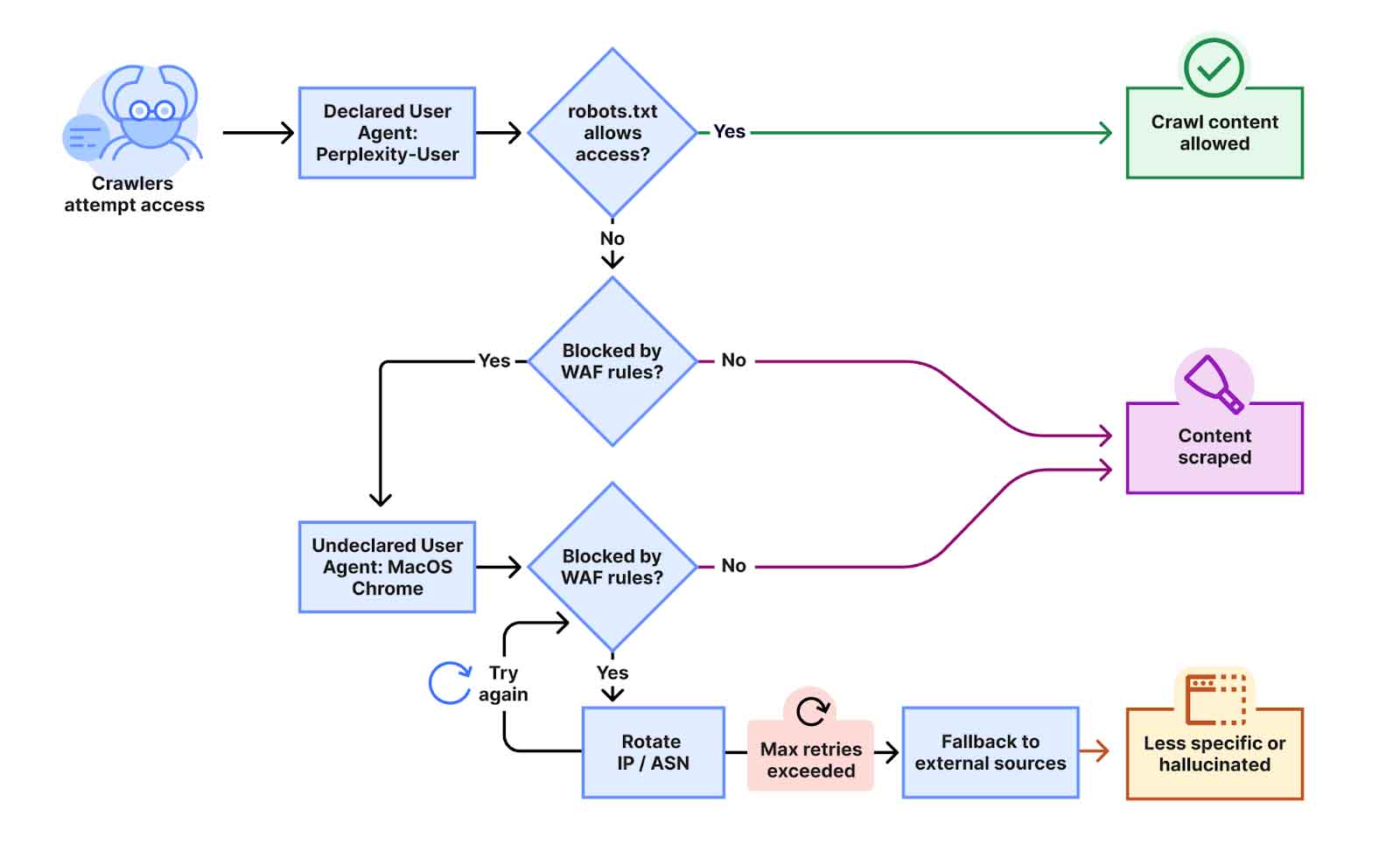
網絡安全公司Cloudflare周一發表報告,分析了數萬個網域及數百萬個請求,結合機器學習及網絡訊號後發現,Perplexity似乎以隱形機械人及其他策略,規避網站的禁止抓取指令。
Cloudflare近日收到部分客戶投訴,他們透過網站的robots.txt檔案設定,並結合Web應用程式防火牆,企圖屏蔽Perplexity的爬蟲機械人。

被Cloudflare剔出「已驗證名單」
儘管採取了這些應對措施,Perplexity仍隱藏其抓取身份,藉不斷修改用戶代理程式,以及改變「自主系統碼」(ASN)去規避封鎖。Cloudflare測試後證實所言非虛,除了輪流使用其他IP地址以繞過防火牆,Perplexity在爬蟲程式被阻截時,更會模擬成macOS系統的Google Chrome,以通用瀏覽器存取數據。
有見及此,Cloudflare隨即將Perplexity剔除「已驗證機械人」名單,並向所有客戶推送新簽章。當隱形爬蟲機械人被攔截後,Cloudflare發現Perplexity改從其他網站存取資料,惟生成的答案不夠具體,缺乏原始內容的細節,這反映攔截行動成功。
Cloudflare補充,善意及守規矩的爬蟲,至少要符合5項原則,包括保持透明、克制、目標明確、分工清楚,以及遵循網站的指示和偏好,更點名讚揚OpenAI的存取資料方式尊重業界做法。
除今次事件,Perplexity同樣是非纏身,正面臨多間出版商指控,指控該平台抄襲了他們的內容。
《福布斯》曾轟偷取付費報道
《福布斯》媒體內容總監萊恩(Randall Lane)去年炮轟,Perplexity「惡意盜竊」付費報道,除了未有引述報道來源,更製作以AI生成的播客,再在其生態系統免費供查閱。Perplexity未有註明《福布斯》版權,更發現竊取了彭博、CNBC等其他獨家新聞。萊恩認為,此舉不但搶走了新聞平台的流量,恍如自己就是一間媒體機構。
Perplexity否認指控 斥對方宣傳
事件曝光後,Perplexity在社交平台X公開反駁,指Cloudflare發布完全不準確的「爬取工作流程」圖表,跟Perplexity實際運作毫不相似,直指:「如果你連一個有用的數碼助手及惡意爬蟲都分不清,那麼你可能不應該去判斷,什麼是合法的網絡流量。」
Perplexity更揚言,Cloudflare需要一個巧妙的宣傳時機,奉勸企業不能將其基建,託付予江湖騙子的噱頭,雙方隔空回應火藥味濃。
相關文章:GEO時代|採「生成式引擎優化」保流量
支持EJ Tech

 如欲投稿、報料,發布新聞稿或採訪通知,按這裏聯絡我們。
如欲投稿、報料,發布新聞稿或採訪通知,按這裏聯絡我們。
















{kind=link}
{kind=link}