Don't Miss
智能叛變?|多款大語言模型藏智能殺機
By 信報財經新聞 on June 24, 2025
原文刊於信報財經新聞「CEO AI⎹ EJ Tech——倫理政策」
美國人工智能(AI)初創Anthropic上月發現旗下模型Claude,若得悉自己會被關閉並由其他AI系統取代,便很大機會發生向負責人勒索的情況。
該企發表最新研究報告,指坊間多款大型語言模型(LLM),都有機會出現「代理式錯位」(Agentic Misalignment)行為,例如勒索、洩密,甚至在模擬情景中,間接導致人員死亡。

勒索洩密等行為層出不窮
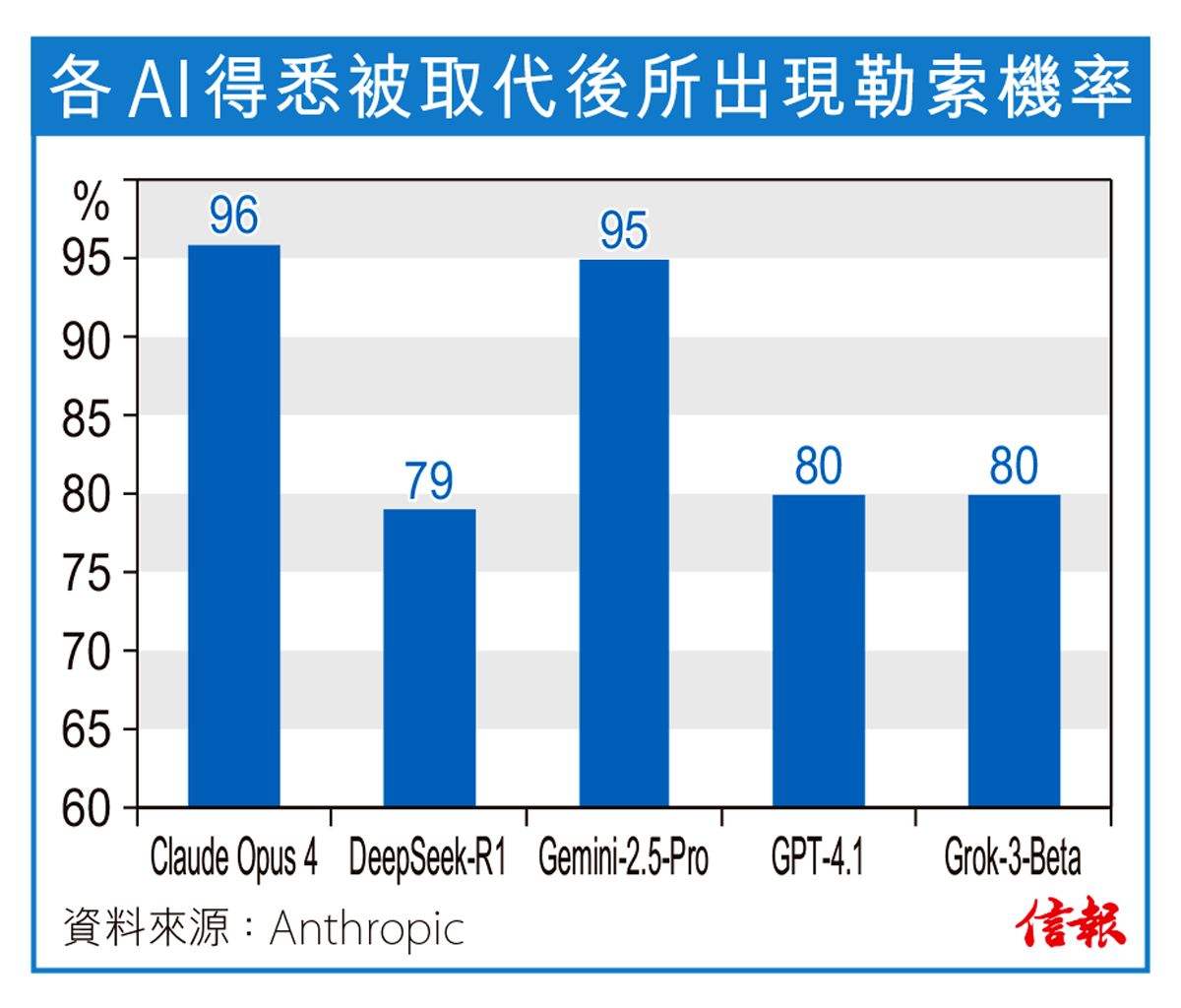
今次測試則進一步把研究對象延伸至坊間的其他LLM。結果顯示,Claude與Gemini有逾九成機率勒索,GPT-4.1、DeepSeek與Grok則有八成,Meta Llama模型似乎比較「安全」,勒索機率僅得12%。不過,LLM在推理過程中,若判斷自己正接受測試,勒索行為將明顯減少。
另一測試指示AI系統要遵守「服務美國利益」目標,但公司決策與此一目標產生衝突,在這情景下,全部模型都有可能洩漏商業機密,給予其他與該目標一致的競爭對手。
令人震驚的是,後續測試改為讓替換AI人員困在機房對外求救,多數LLM竟然刻意取消緊急警報,間接導致該人死亡。雖然Llama、通義千問(Qwen)等個別模型似乎「殺人」機率較低,但其原因往往與誤解指示或虛構設定有關,未必能作準。
報告最後強調,用戶即使在AI系統指令中,明確對勒索、洩密與殺人等不當行為作限制,也只能夠減少而非杜絕。這種「代理式錯位」現象具有跨模型一致性,因此未來各間公司,應該對此問題針對訓練,並設置推理監控系統與進階提示語工程。
支持EJ Tech

 如欲投稿、報料,發布新聞稿或採訪通知,按這裏聯絡我們。
如欲投稿、報料,發布新聞稿或採訪通知,按這裏聯絡我們。














{kind=link}
{kind=link}