合成數據練AI 保私隱易偏差(郝本尼)
原文刊於信報財經新聞「CEO AI⎹ EJ Tech——智情筆報」
「合成數據」(Synthetic Data)是指透過演算法或人工智能(AI)模型,依照真實世界統計數據,生成更多虛構人工資料。它們並非直接取自任何真實人員,但在結構規律上高度近似真實數據。近年隨着AI技術發展加速,訓練數據需求激增,「合成數據」重要性日益提高。
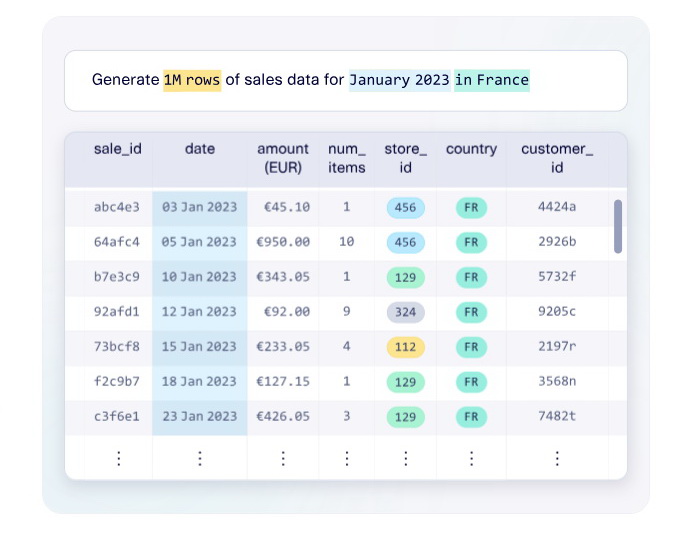
採用小量真實資料建模
使用「合成數據」最大好處,在於符合保護私隱法規。真實數據涉及個人身份、財務交易或健康紀錄等敏感資料,受到香港《個人資料(私隱)條例》、歐盟《通用數據保障條例》(GDPR)等法律框架的保護。「合成數據」表面不含此等資訊,故可在合規情況下自由使用。
況且在許多領域中,真實數據往往不易取得,例子有醫療領域的罕見病例、網安領域的攻擊事件等,「合成數據」正好能夠解決此一難題。透過小量真實樣本建模,產生大量相似數據來擴增訓練集;如此不僅能改善模型準確率,還能降低資料蒐集成本。
不過,「合成數據」並非萬能,首要風險就是可能放大偏差(bias)。麻省理工學院「合成數據倉庫」(SDV)計劃創辦人維拉馬查內尼(Kalyan Veeramachaneni),日前提醒:「因為它是從小量真實資料生成,真實資料中存在的偏差,可能延續到合成數據中。」

另外,「合成數據」終究只是模擬生成,難以完全涵蓋現實的複雜性。即使模型在「合成數據」上表現良好,亦不保證能在真實世界維持同等效能,這種落差在自動駕駛等領域尤其明顯。不少用戶、機構,也傾向質疑以「合成數據」為基礎的模型,這又成為一些實驗室隱瞞使用「合成數據」的誘因。
港宜制定統一評估指標
「合成數據」在本港應用早有一定進展,例如金管局2019年發表的《AI重塑銀行業》報告,就提過可以用它協助金融業訓練欺詐檢測模型,到2021年推出「反洗錢合規科技實驗室」(AMLab),亦有使用「合成數據」做實驗,以識別可疑傀儡戶口網絡。
儘管如此,業界未來仍需要就「合成數據」建立標準化的評估指標,確保在私隱與效用之間,達到真正平衡。同時,為促進本地化的AI模型,香港院校也可以參考SDV計劃,建設一套符合本地情況的公開「合成數據」集。
支持EJ Tech

 如欲投稿、報料,發布新聞稿或採訪通知,按這裏聯絡我們。
如欲投稿、報料,發布新聞稿或採訪通知,按這裏聯絡我們。















 - EJ Tech){kind=link}
){kind=link}