Don't Miss
幻覺減弱|GPT-5出現「幻覺」機率減至4.8%
By 信報財經新聞 on August 11, 2025
原文刊於信報財經新聞「CEO AI⎹ EJ Tech」
在啟用網頁搜尋後,GPT-5模型準確率顯著提升,回應包含事實錯誤或虛構內容的機率,比GPT-4o低約45%;在「思考」狀態下,錯誤機率亦比o3模型低約80%。在長篇內容基準測驗中,具有思考能力的GPT-5,虛構內容則比o3少約6倍。在ChatGPT提示回應中,具思考能力的GPT-5,出現「幻覺」並提供錯誤訊息的機率為4.8%,比GPT-o3(22%)及GPT-4o(20.6%)大減。
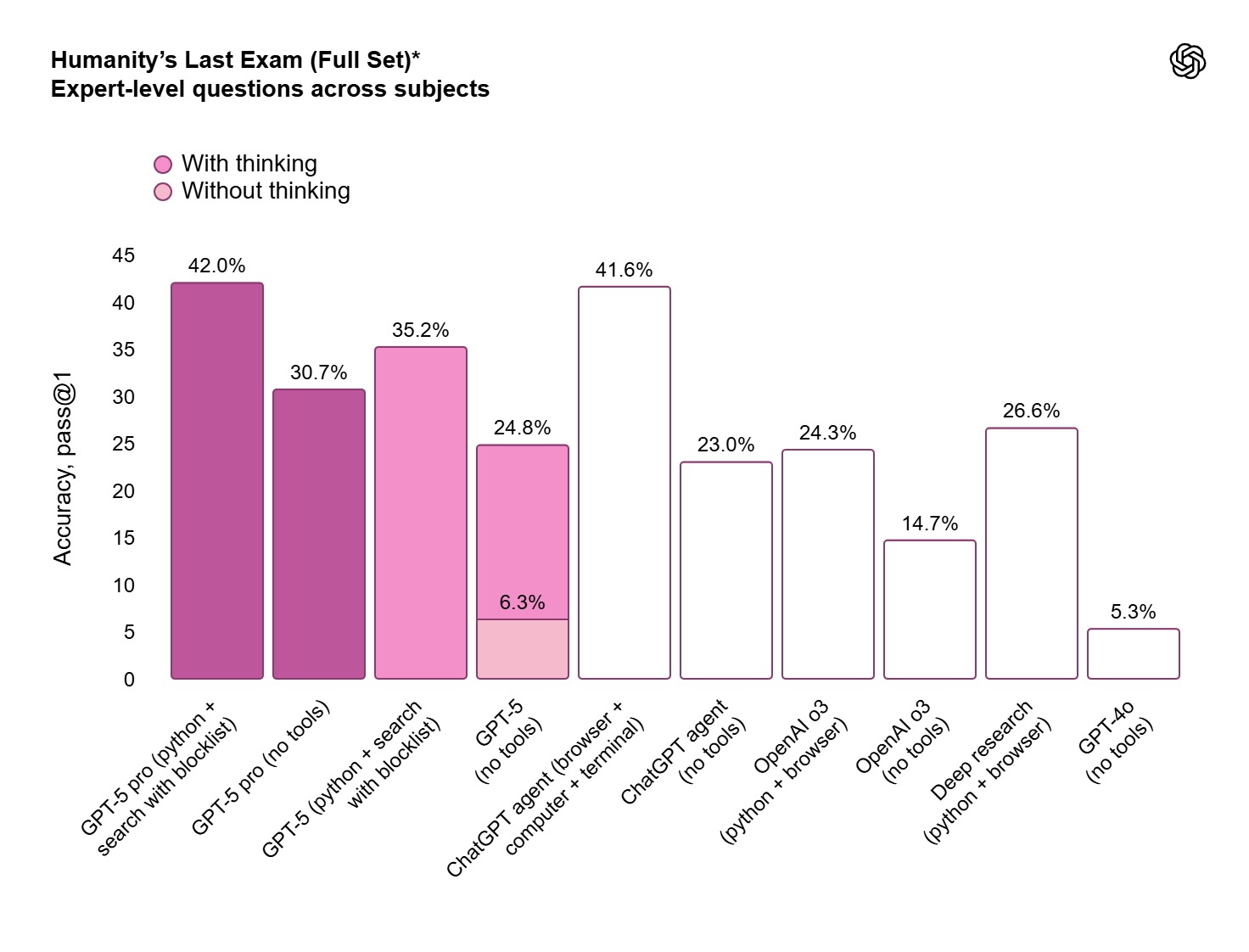
基準測試跑分方面,衡量編程能力的SWE-bench Verified,GPT-5得分74.9%,表現略勝Anthropic最新模型Claude Opus 4.1(74.5%)及谷歌DeepMind Gemini 2.5 Pro(59.6%)。在「人類終極考驗」(HLE),具有擴展推理功能的GPT-5 Pro,在使用工具下得分42%,成績略低於xAI Grok 4 Heavy(44.4%)。針對博士級科學問題的GPQA Diamond,GPT-5 Pro得分89.4%,超越Claude Opus 4.1(80.9%)及Grok 4 Heavy(88.9%)。
網上代理任務測試遜色
專門知識方面,在OpenAI開發的醫療測試HealthBench Hard,GPT-5得分46.2%。在數學測試AIME 25,GPT-5毋須工具協助取得94.6%。在多模態理解測驗MMMU,GPT-5表現達84.2%。不過,在網上代理任務測試Tau-bench,GPT-5瀏覽航空公司網站得分僅得63.5%,略低於o3的64.8%;而瀏覽零售網站時得分也是81.1%,略低於Claude Opus 4.1的82.4%。
相關文章:
支持EJ Tech

 如欲投稿、報料,發布新聞稿或採訪通知,按這裏聯絡我們。
如欲投稿、報料,發布新聞稿或採訪通知,按這裏聯絡我們。

















{kind=link}
{kind=link}