防AI盜內容|Cloudflare防AI爬蟲盜內容 助網站落閘報價 付款始可抓取資訊
原文刊於信報財經新聞「CEO AI⎹ EJ Tech」
美國網絡安全公司Cloudflare宣布把7月1日定為「內容獨立日」(Content Independence Day),並提出一系列措施協助網站阻止人工智能(AI)公司任意抓取資訊,讓網絡出版商或創作人能為自家內容爭取合理報酬。
剽竊猖獗 重創出版商流量
過去人們瀏覽網站主要依賴搜尋引擎,先由搜尋引擎抓取部分內容,再引導人流到出處網站,讓創作人獲得變現機會。無奈隨着AI工具崛起,這種運作模式逐漸失效,各間AI科企透過大量爬蟲程式,抓取全網資訊以訓練模型或提供服務,卻又極少回傳真人流量,大幅扼殺網站生存空間。
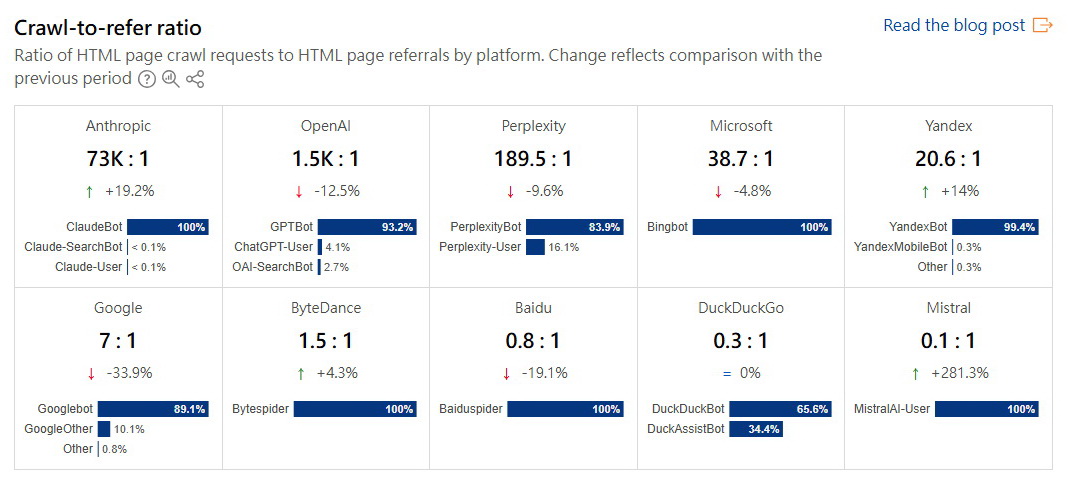
Cloudflare今年3月寫道:「AI爬蟲每天向Cloudflare網絡發出超過500億個請求。」公司近期分析AI爬蟲數據【見表】,發現過去一年AI爬蟲的總流量增長了18%,當中Google爬蟲流量幾乎倍增,OpenAI自家GPTBot爬蟲有逾3倍增長,與其用戶互動相關的爬蟲更急升28倍;升幅最誇張的是Perplexity爬蟲,高達1574倍。

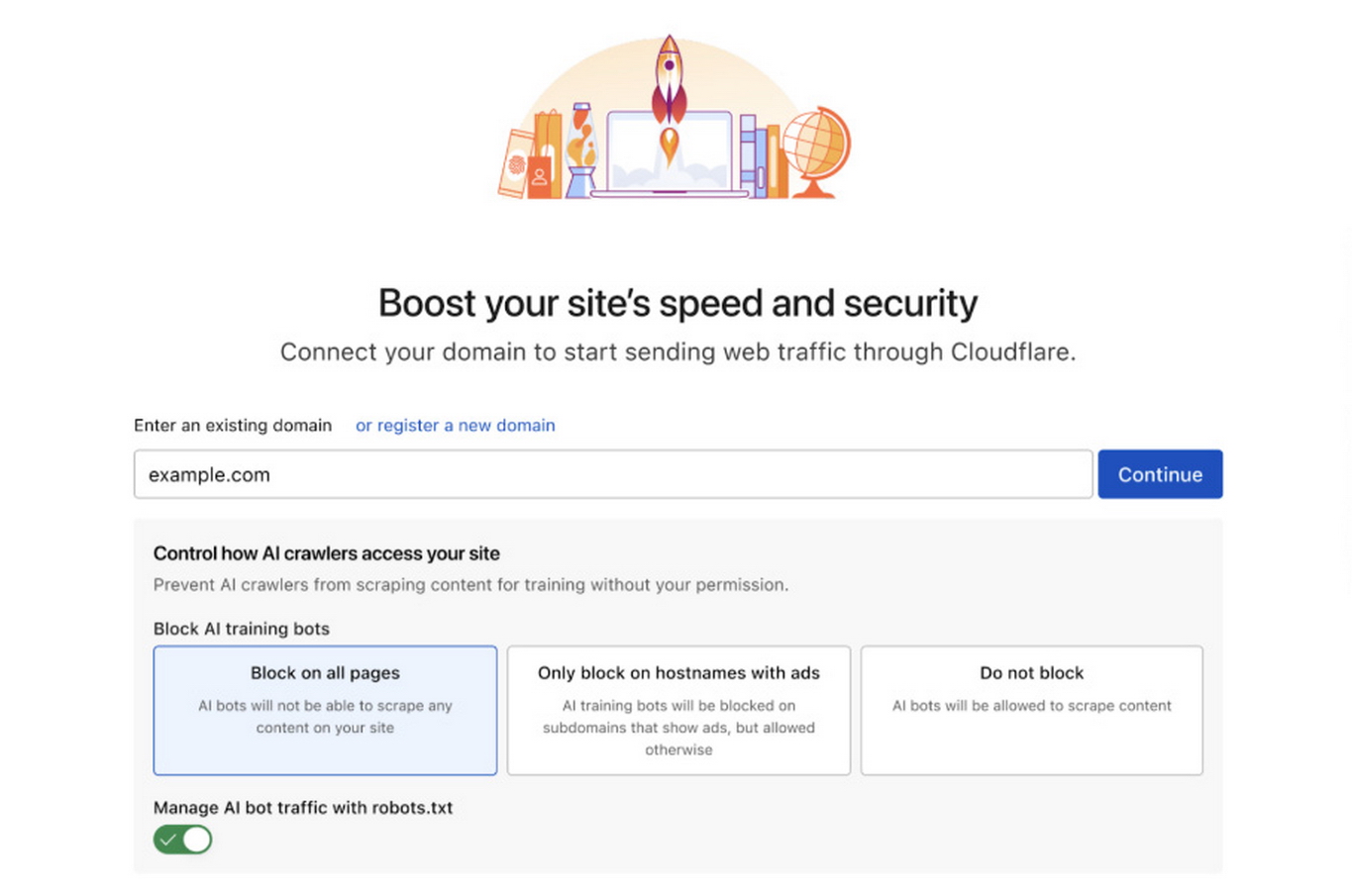
面對AI爬蟲猖獗局面,Cloudflare在旗下平台推出一套全新應對機制──「按爬收費」(Pay Per Crawl),將允許網站擁有人針對AI爬蟲,設定每次請求的收費規則,並透過HTTP 402「所需付款」狀態碼回應,做法如向AI爬蟲開出「報價單」。這樣對方若想繼續抓取資料,首先要表達付款意圖。
為防止冒用爬蟲或偽造付款請求等情況,Cloudflare還利用網站機械人身份驗證(Web Bot Auth)驗證技術,要求AI爬蟲註冊公鑰與用戶代理資訊,而且每次請求都須提交憑證,確保只有經認證的爬蟲,能參與付費存取與結算流程,保障內容提供方的利益與安全。
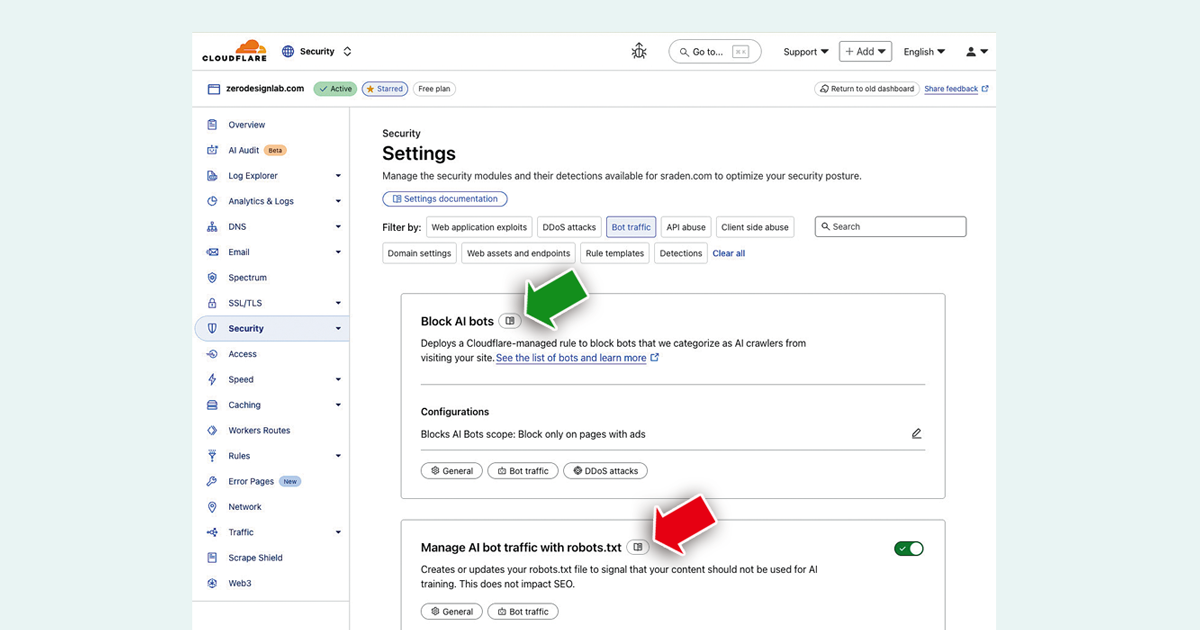
對於未準備啟用收費系統的網站,Cloudflare也會提供兩項免費保護機制。
CEO:為創作者爭取合理報酬
其一是託管robots.txt,現時這個用來控制內容存取規則的文件利用率不高,而Cloudflare可代勞產生或更新,從而自動封鎖AI爬蟲;其二是容許僅在廣告頁面封鎖AI爬蟲,以配合那些不希望全站封鎖,卻想保護收益來源的出版商或創作人。

Cloudflare聯合創辦人及行政總裁普林斯(Matthew Prince)說:「網絡正在改變,其商業模式也將隨之改變。這個過程中,我們有機會從過去30年網絡的成功經驗學習,並為未來的網絡打造更好模式……我對我們所扮演的角色感到驕傲,因為我們正幫助內容創作人挺身而出,讓他們辛苦創作的內容獲得應有價值。」
支持EJ Tech

 如欲投稿、報料,發布新聞稿或採訪通知,按這裏聯絡我們。
如欲投稿、報料,發布新聞稿或採訪通知,按這裏聯絡我們。
















{kind=link}
{kind=link}