Don't Miss
AI準確率報告|最高僅69%
By 信報財經新聞 on December 17, 2025
原文刊於信報財經新聞「CEO AI⎹ EJ Tech」
時下大多數人工智能(AI)測試,都專注於模型能否完成任務,而非針對其生成的資訊是否真實。谷歌(Google)近日發布一份研究報告,透過其新推出的FACTS基準測試套件,以評估當今人工智能(AI)聊天機械人的可靠性。結果發現,即使最好的AI模型(Gemini 3 Pro),事實準確率也難以突破70%【見表】。來自OpenAI、Anthropic、xAI等其他系統得分亦較低,仍會答錯大約三分一問題。
Claude及Grok約有一半錯誤
FACTS基準測試套件由Google FACTS團隊與Kaggle合作開發,直接測試模型在4個場景的事實準確性。第一項測試衡量參數知識,即檢驗模型能否僅使用訓練期間學習的知識,回答基於事實的問題;第二項測試評估搜尋效能,檢驗模型使用網絡工具,檢索準確資訊的能力;第三項測試着重「扎根性」,即模型能否忠實理解所提供的文檔,而不添加錯誤訊息;第四項測試檢視多模態理解能力,例如正確解讀圖表、示意圖及圖像的能力。
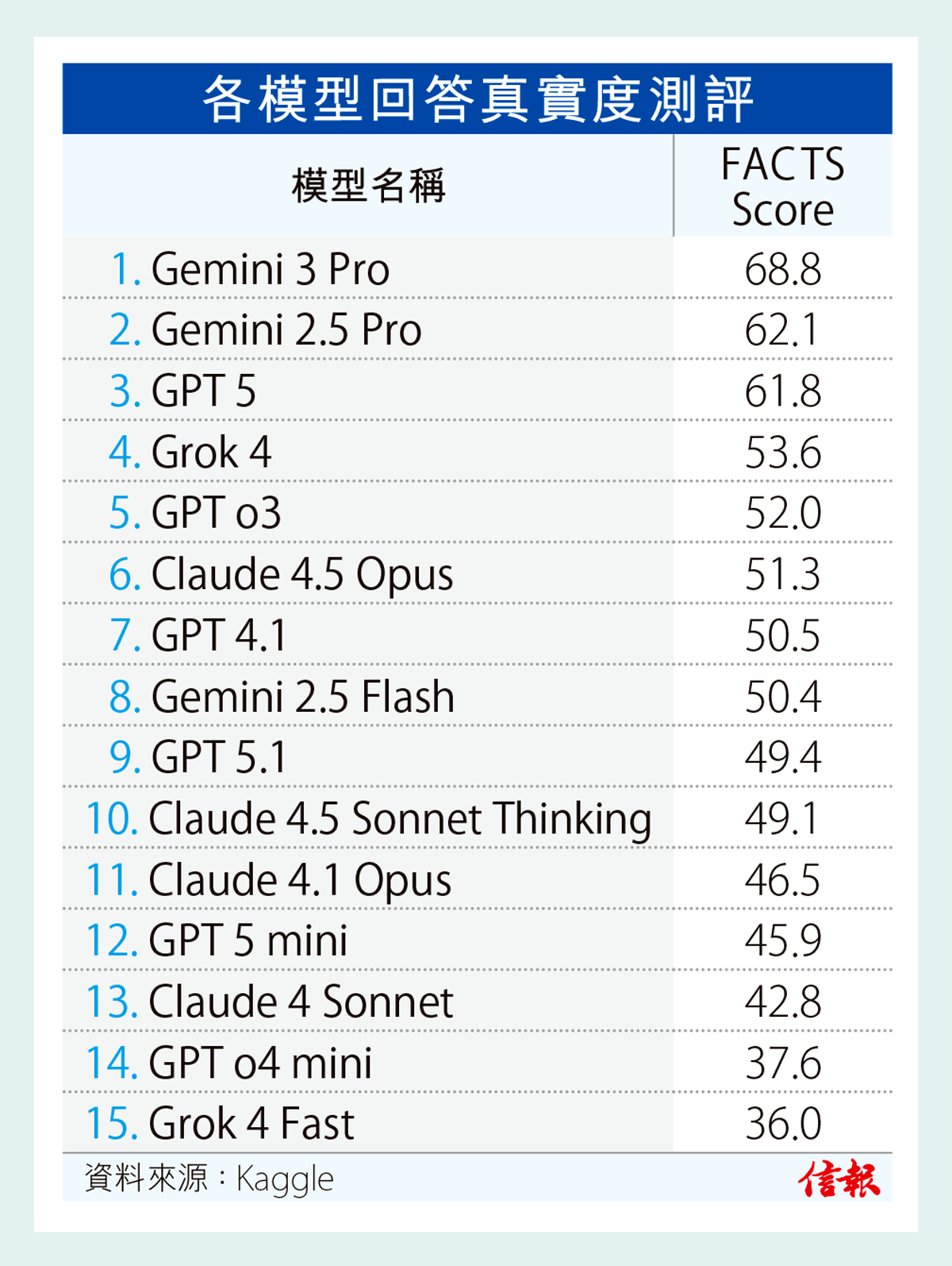
測試成績顯示。Gemini 3 Pro以69%的FACTS得分位居榜首,緊隨其後是Gemini 2.5 Pro及OpenAI GPT 5,得分約62%。Claude 4.5 Opus得分為51%,Grok 4得分接近54%。對需要精準數據的行業,例如金融、醫療保健、法律等,盲目信任聊天機械人將存在風險,不實資訊隨時釀成巨大損失。當AI模型成為可靠資訊來源之前,仍需驗證、監管及人類監督。
支持EJ Tech

 如欲投稿、報料,發布新聞稿或採訪通知,按這裏聯絡我們。
如欲投稿、報料,發布新聞稿或採訪通知,按這裏聯絡我們。
















{kind=link}
{kind=link}