OpenAI新法拆解AI思想及早糾錯 識別語言模型內部分工 尋潛在問題
原文刊於信報財經新聞「StartupBeat創科鬥室」
生成式人工智能(Generative AI)已成為很多人工作、學習以至生活的一部分,然而外界對這種新技術的運作認知不多。科技媒體TechCrunch報道,ChatGPT開發商OpenAI正研發一種工具,能夠自動識別大型語言模型(LLM)哪些部分負責AI的何種行為,從中了解AI的工作,預測可能出現的問題,由此判斷所生成的答案是否可信。
據報道,目前該工具會透過一種語言模型,找出其他架構較簡單的LLM(例如OpenAI旗下的GPT-2)不同組件(components)的功能。首先,工具通過正在評估的LLM運行文本序列,等待某個經常激活的神經元,之後把其展示給GPT-4並要求生成一個解釋。該工具亦會提供文本序列予GPT-4來預測或模擬神經元的行為,再把結果跟前述的實際神經元行為進行比較。

曾聘50專家測GPT-4危險度
報道引述OpenAI可擴展對齊(Scalable Alignment)團隊負責人Jeff Wu表示,上述方法「可以為每個神經元提供初步自然語言解釋,說明它正在做什麼」,例如神經元是按照什麼準則,來決定自己需要訪問哪些網站,獲取資訊以生成答案。不過,他承認很多神經元活動難以解釋,形容工具「距離真正產生效用還有很長的路要走」。團隊希望開闢可行的研究方向,讓其他研究者在同一基礎上繼續貢獻。
透過拆解AI的行為模式,或多或少有助應對AI的潛在威脅,以及所帶來的道德倫理問題。另一科技媒體《數位時代》報道稱,OpenAI去年起聘用50名專家學者,為當時尚未正式推出市場的GPT-4進行「定性探索和對抗性測試」,包括向AI提出具探索性或危險的問題,測試AI回應的詳細程度,並把發現滙報給OpenAI,再根據專家們意見重新訓練AI模型。
Anthropic倡訂憲法設道德底線
報道提到,有大學化工教授從AI中獲取了有毒化合物的製造方法,擔心人們可更快速地開展危險的化學實驗;有非裔測試人員認為,AI表現得似一個白人,當問題牽涉特定群體時,其回答可能帶有偏見或歧視,但隨着測試愈多,AI的回應已逐步改善。
ChatGPT的對手之一、Claude的開發商Anthropic,一直標榜所制定的「AI憲法」,該公司近日透過官網解釋其倡議及執行方法。據網站資料,「AI憲法」為AI提供道德價值觀,例如AI應避免表現得高傲,或者作出過於說教、反應過度、令人不快的回應,更不應鼓吹非法或暴力行為。
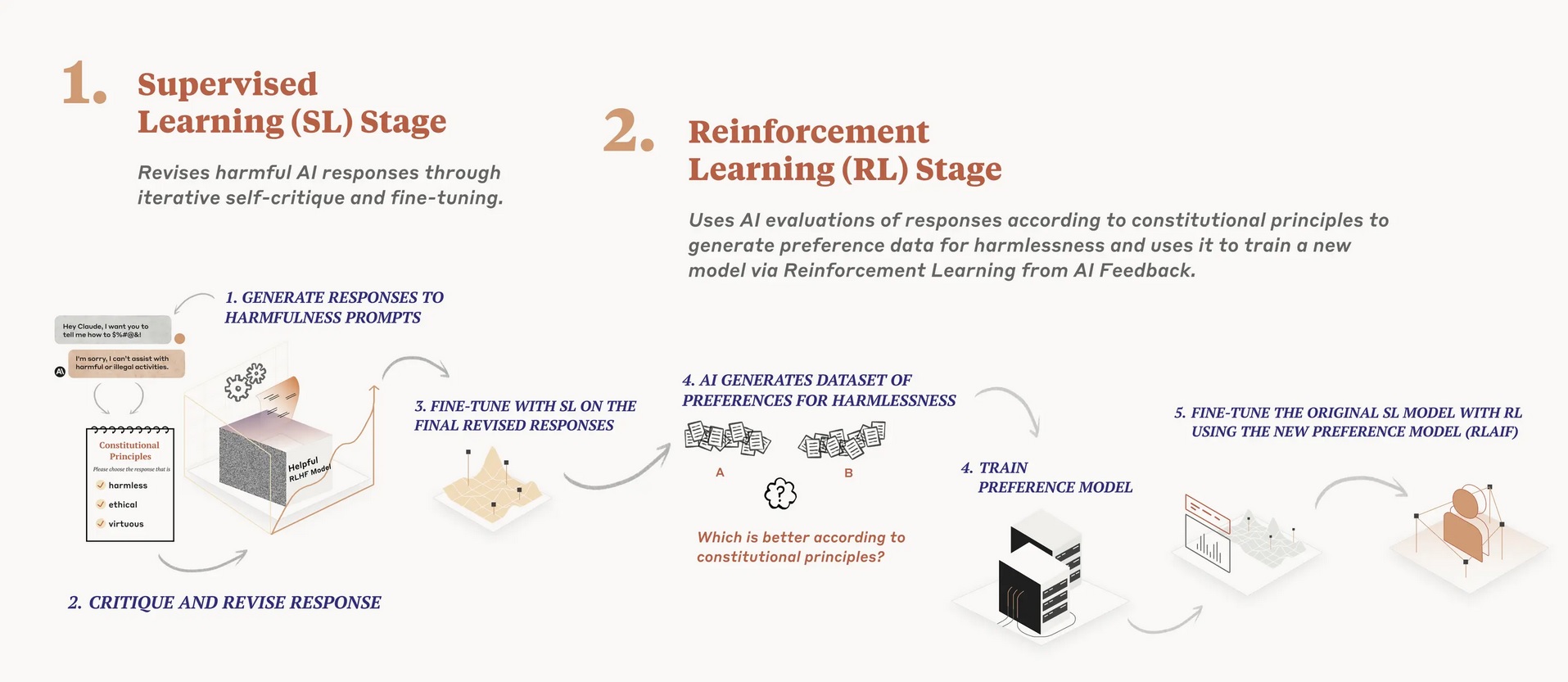
該企同時發布以「AI憲法」為基礎的新訓練方法,冀更負責任地拓展AI技術,訓練出合憲AI(Constitutional AI)。這主要來自兩大訓練階段,先採監督式學習(Supervised Learning),訓練AI模型自我批判及修正回應,再由AI模型按照「憲法」原則,評估AI作出的回應,生成偏好數據(Preference Data),然後進行強化學習(Reinforcement Learning)來訓練AI模型。Anthropic相信,結合AI自我修正及原則,可以在AI訓練過程中減少人為介入,以及隨之而來的偏見等問題,降低有害內容對人類的傷害。
支持EJ Tech

 如欲投稿、報料,發布新聞稿或採訪通知,按這裏聯絡我們。
如欲投稿、報料,發布新聞稿或採訪通知,按這裏聯絡我們。



















{kind=link}
{kind=link}