AI協助夢境解讀(郭德偉)
本文作者郭德偉(Andy Kwok),為數據及人工智能素養協會 (DALA)資深創會會員 兼 OpenCertHub 創辦人及行政總裁 ,為《EJTech》撰寫專欄
自古以來,人類對夢境的探究充滿好奇,將其視為通往潛意識的接口、預示未來的徵兆,或是超現實的體驗。然而,夢境的本質難以捉摸且極為個人化,使得其客觀研究困難重重。隨著科技的高速發展,特別是人工智能 (AI) 與腦部影像技術的結合,過去只限於科幻小說中出現的「解讀夢境」情節正在逐步成為現實。
說到這裏,我想起已故日本動畫大師今敏的經典作品 -《盜夢偵探》(Paprika)。這個創作於2006年的動畫作品以AI及夢境為題材,它不僅預示了AI解讀夢境技術的潛力,也深入探討了其可能帶來的倫理挑戰與社會影響。 此作品亦同時啟發荷里活名導演基斯杜化路蘭,創作了《潛行凶間》(Inception, 2010) 這部賣座電影。

大腦的夢境數據
以現今技術而言,AI 解讀人類夢境主要是依賴功能性磁振造影 (fMRI) 的數據作分析,探索夢境的神經基礎。此領域的突破性研究,可追溯至2013年由奈良先進科學技術大學院大學 (Nara Institute of Science and Technology) 的堀川博士 (Dr. HORIKAWA Tomoyasu) 及其團隊所發表的研究報告。 該報告所提及到的「睡眠時視覺想像的神經解碼」,已初步證明了從神經訊號中解讀夢境內容的可能性。
直到2025年1月,上海復旦大學數據科學學院的付彥偉教授 (Yanwei Fu) 所領導的研究團隊,撰寫了一份報告名為 : “Making Your Dreams A Reality: Decoding the Dreams into a Coherent Video Story from fMRI Signals”,當中提出了一個將夢境轉化為連貫影片敘事的新穎框架,並以 fMRI 數據進為基礎。透過使用 fMRI,研究人員現在可以看到睡眠期間大腦的哪些部分活躍,並將這些模式與人們醒來後描述的故事和情感聯繫起來,這個大膽的新想法標誌著多媒體和夢境研究領域的重大進展。同時利用AI 大型語言模型 (LLM – An Automatic Framework for Dynamic Visual Composition using ChatGPT) 來解釋解碼後的影像,並將它們整合到全面的夢境體驗中,以呈現文本描述。
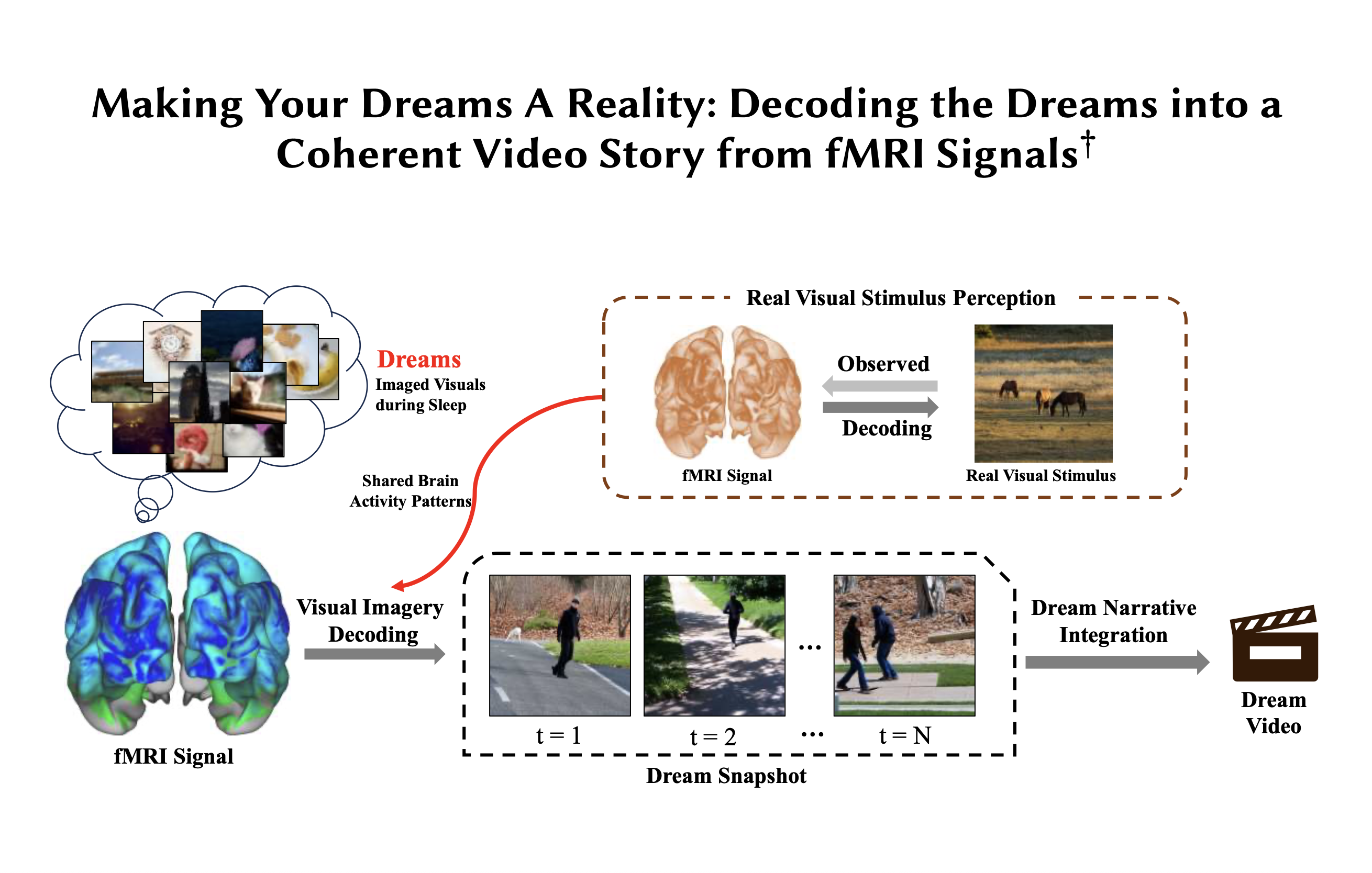
AI 如何「讀懂」夢
付教授他們設計的方法涉及幾個重要步驟。首先將 fMRI 解碼與涉及真實和想像視覺的任務相結合,並將不連貫的夢境圖像轉化為完整的敘事。 他們將 fMRI 掃描解碼夢境的詳細過程分為以下三個主要部份 :
- 重建視覺刺激感知 (Reconstructing Visual Stimulus Perception)
- 此階段的目標是訓練 AI 模型,使其能夠從清醒狀態下的大腦活動中重建視覺圖像。研究人員會讓清醒的測試者觀看真實圖像,並同步記錄其 fMRI 數據。
- 由於夢境數據稀缺且缺乏真實視覺圖像作為訓練依據,此階段會利用大規模的 fMRI-圖像數據集,例如「自然場景數據集」(Natural Scenes Dataset, NSD),該數據集包含來自八位受試者的超過 65,000 張圖像及其對應的 fMRI 訊號。
- 研究利用諸如 NeuroPictor 等模型,透過轉換器編碼器(transformer encoder)將 fMRI 數據轉換為統一的表示形式,再結合擴散生成模型(diffusion generative model)來重建視覺圖像。這樣訓練的模型能夠學習跨個體且廣泛的圖像重建能力。
- 堀川博士等人的早期研究發現,夢境中的特定視覺體驗與清醒時感知視覺刺激的大腦活動模式是共享的。這項發現為將從清醒狀態訓練的模型應用於夢境解碼奠定了基礎。
- 解碼夢境視覺意象解碼 (Decoding Dream Visual Imagery)
- 在建立了能夠重建真實視覺刺激的模型後,研究人員會將其應用於睡眠期間採集的 fMRI 數據。
- 透過分析睡眠狀態下的 fMRI 數據,AI 系統能夠從連續的大腦活動中解碼出離散的「虛擬視覺幀」(virtual visual frames),這些圖像代表了受試者在特定時間點的夢境內容。
- 與過去僅能進行「語義類別分類」(semantic category-level classification) 的方法不同,目前的目標是實現「精確重建夢境中細緻的視覺體驗」,直接將夢境內容視覺化,而非僅僅識別物體類別。堀川博士最初的研究只能辨識「活物」與「非活物」等粗略類別,或約 20 種預設物體和場景: 如「汽車」、「男性」、「街道」等。而現代 AI 則追求更精確的圖像重建。
- 整合夢境敘事 (Integrating Dream Narratives)
- 夢境並非孤立的圖像,而是連貫的敘事序列。因此,僅僅重建單一圖像並不足以捕捉完整的夢境體驗。
- 此階段利用AI 大型語言模型 (LLMs) 的強大能力,將解碼出來的零碎夢境圖像整合為連貫的視覺敘事。具體流程包含以下三個部分:
- 單一鏡頭夢境描述 (Single-Shot Dream Description):運用圖像-文本問答模型 (如 LENS) 為每個解碼圖像生成詳細的文字描述。
- 夢境故事創作 (Dream Story Composition):利用 LLM根據這些圖像描述,創作一個具有夢境風格且邏輯連貫的敘事腳本,包括夢境標題、結語和推薦的音軌。
- 影片整合 (Video Integration):將這些解碼圖像、生成的文字腳本、標題、結語和音軌結合,創造出一部完整的夢境敘事影片。
未來發展與潛在應用
這項前瞻性的AI技術發展,開啟了多方面的可能性:
- 深入理解夢境與潛意識:AI 解碼能夠提供客觀的夢境視覺數據,使研究人員能更深入地探索夢境的「神經基礎」、夢境中「視覺體驗」的細節,以及夢境生成背後的大腦機制。這有助於彌合「主觀體驗」與「客觀神經生理數據」之間的鴻溝。
- 心理治療與精神健康:AI 解碼的夢境內容,有望成為心理治療的輔助工具。透過視覺化患者的夢境,治療師或許能更直觀地理解其潛意識衝突、焦慮和未竟之事,從而制定更精準的治療方案。此外,這些客觀的夢境視覺呈現,也能幫助患者主動參與到夢境分析中,促進「內在和解」與「自我成長」。
- 輔助新興夢境療法:雖然 AI 解碼本身與「清醒夢」 (lucid dreaming) 不同,但其成果可能間接輔助清醒夢等療法的發展。清醒夢被證明對創傷後壓力症候群 (PTSD) 的治療具有顯著效果。如果 AI 能夠提供清晰的夢境內容,患者和治療師就可以在清醒狀態下分析這些圖像,甚至設計「治療性夢境」情境,以更有效地引導清醒夢者在夢中處理創傷。堀川博士也曾提到,該方法除了用於解讀夢境,還可能用於研究「自發性神經活動」或「診斷幻覺等神經疾病」。
- 創意表達與娛樂體驗:想像一下,將自己天馬行空的夢境轉化為一部個人影片,與他人分享。這將為藝術家、作家和普通大眾提供全新的「創意表達可能性」,將「夢想變為現實」,創造出前所未有的「個性化」視覺內容。
- 人機互動的新範式:隨著技術的成熟,我們甚至可以設想未來 AI 系統能夠在夢境中與人類進行某種形式的互動,或者生成基於個人夢境的沉浸式虛擬現實體驗。

《盜夢偵探》的啟示
AI 解讀人類夢境的技術,正從科幻走向現實,預示著對人類意識和潛意識理解的巨大飛躍。從 fMRI 數據中重建視覺感知,到利用 LLMs 整合夢境敘事,這項技術正不斷突破界限,有望在心理健康、創意產業等領域帶來革命性的變革。同時,今敏的《盜夢偵探》 則如同一個前瞻性的寓言,這部動畫作品為我們理解當前的科學進展,並思考其未來走向提供了豐富的啟示。
影片中的Dream Machine裝置允許人們進入他人夢境,尋找潛意識中的心理疾病根源,並進行治療。這與現實中 AI 透過 fMRI 解碼夢境的目標異曲同工。雖然目前 AI 僅能「被動」解讀,但電影中的「進入」和「治療」夢境,暗示了未來 AI 可能發展出更「主動」干預夢境的能力。我們在追求科技進步的同時,必須審慎思考其可能引發的倫理、社會和哲學問題。如何確保這些技術能被善用,以促進人類福祉而非製造混亂,將是我們在「解碼夢境」之旅中,必須不斷面對和深思的課題。
更多郭德偉文章:
支持EJ Tech

 如欲投稿、報料,發布新聞稿或採訪通知,按這裏聯絡我們。
如欲投稿、報料,發布新聞稿或採訪通知,按這裏聯絡我們。













 - EJ Tech){kind=link}
){kind=link}