Don't Miss
人機協作生產力|Sonnet 4最標青
By 信報財經新聞 on November 18, 2025
原文刊於信報財經新聞「CEO AI⎹ EJ Tech」
美國自由職業平台Upwork近日公布「人類+代理生產力指數」(HAPI)初步研究結果,是業界首個使用現實工作數據,評估人工智能(AI)代理效益的評估體系。結果發現,Claude Sonnet 4在人類提出意見後,任務完成率達51.2%,表現最出色。

使用現實工作數據作評估
HAPI建基於該企的勞動市場基準測試UpBench,其資料集包含322筆真實成交的固定價格工作,涵蓋會計、行政、數據分析、工程、行銷、翻譯、軟件開發及寫作八大領域。
Upwork還邀請一批頂尖的自由工作者參與評估,他們負責撰寫具體評分規準,標示關鍵、重要、加分或減分項,並視情況要求AI代理再作出嘗試。
根據測試結果,在單靠AI代理處理任務下,Claude Sonnet 4、Gemini 2.5 Pro與OpenAI GPT-5這3款主流通用模型,完成率分別只有39.8%、19.9%與19.6%。
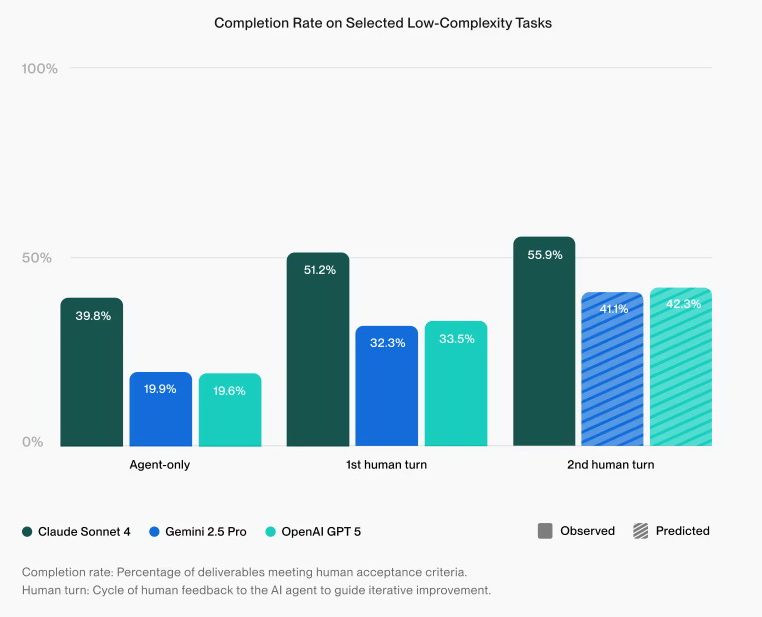
不過,若由人類對AI代理的首次輸出作回饋意見,3款模型任務完成率可增至51.2%、32.3%與33.5%,在加入兩輪回饋意見之後,更能進一步升至55.9%、41.1%與42.3%。
此外,如果細分不同領域工作的話,AI代理在數據分析、軟件開發的表現相對突出,惟行銷、翻譯、寫作等任務比較需要人類指導。
研究同時發現,AI代理最常出錯之處,是成果格式和內容(15.49%)、試算表欄位(9.37%)、財報結構和數據(7.48%)等,反映其對細節操作仍有不足。
另需注意的是,上述HAPI研究目前僅屬初步階段,正式成果仍有待下月美國聖地牙哥舉行的神經資訊處理系統大會(NeurIPS)發表。
支持EJ Tech

 如欲投稿、報料,發布新聞稿或採訪通知,按這裏聯絡我們。
如欲投稿、報料,發布新聞稿或採訪通知,按這裏聯絡我們。

















{kind=link}
{kind=link}