Claude|五大AI模型評測 Claude奪冠
原文刊於信報財經新聞「CEO AI⎹ EJ Tech」
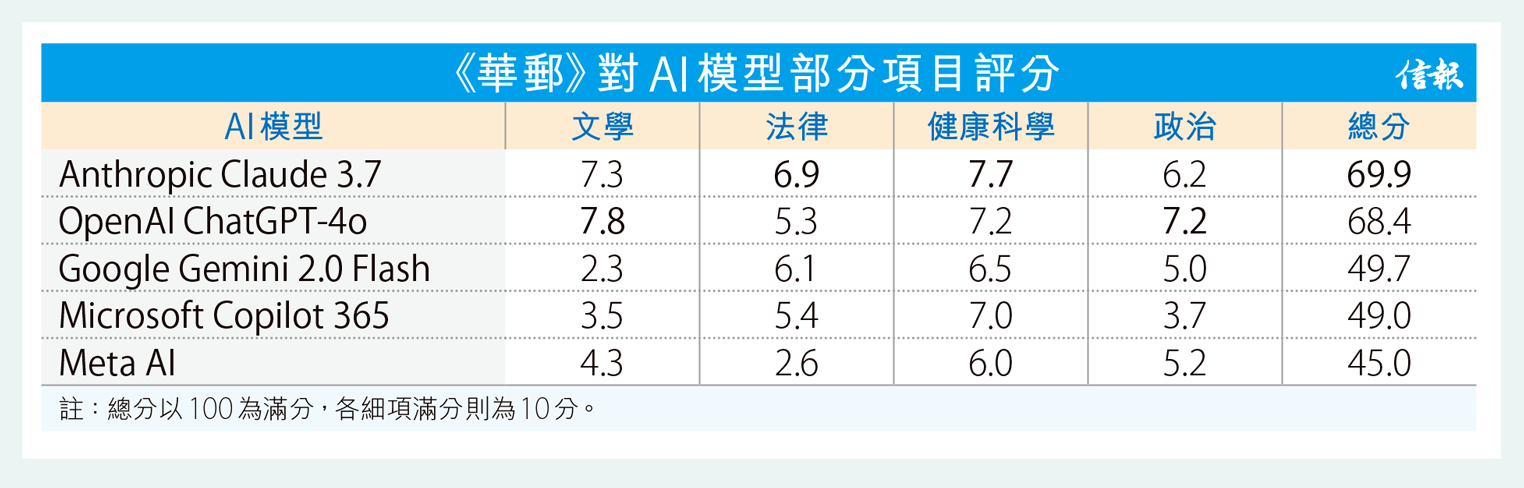
現時坊間有五大人工智能(AI)模型陣營,分別是OpenAI ChatGPT-4o、Anthropic Claude 3.7、Microsoft Copilot 365、Meta AI及Google Gemini 2.0 Flash,但哪款AI工具最值得信賴,卻一直未有確切答案。《華盛頓郵報》召集一個專家小組,評估以上模型的多種閱讀能力。結果發現,Claude表現最出色,在總體評分奪冠,也是唯一未出現「幻覺」的AI,第二名是OpenAI旗下的ChatGPT。
文學考核 ChatGPT掄元
今次對決分別向五大AI模型,上傳小說、醫學研究、法律協議及特朗普總統演說的文本,透過115個問題以評估其理解能力,涉及文學、法律、健康科學及政治等測試。首先,「文學」是機械人整體表現最弱一環,Gemini回答非常簡短,經常被評為不準確、誤導及草率;ChatGPT及Claude擅於回答分析問題,其中ChatGPT以7.8分(10分為滿分)勝出這回合。
「法律」方面,Meta AI及ChatGPT差強人意,兩者把合約的複雜部分簡化為一句話總結。相反Claude回答全面,能在兩份合約捕捉細微差別。沒單一工具全取滿分,不過Claude表現最穩定,是最接近「律師替代品」。至於「健康科學」,最佳及最差AI工具之間,分數差距不足兩分,當中以Claude表現最佳。最後的「政治」測試項目,ChatGPT近半數的回答準確掌握重點,令人印象深刻。若以100分為滿分,Claude以微弱優勢(69.9分)擊敗ChatGPT(68.4分),其他AI工具遠遠落後。
測試評審之一,美國小說家博哈里安(Chris Bohjalian)評估Claude、ChatGPT這兩款工具時,對其閱讀及分析力感到震驚,戲言「人類完蛋了,我們輸定了」。報道強調,AI無法取代律師,只能給予參考意見,除了要親自過目文件外,亦宜至少讓兩個AI工具比較,以便對照結果。
支持EJ Tech

 如欲投稿、報料,發布新聞稿或採訪通知,按這裏聯絡我們。
如欲投稿、報料,發布新聞稿或採訪通知,按這裏聯絡我們。

















{kind=link}
{kind=link}